階層構造とは
いわゆるTree Strcture(木構造)。
例として上げるのであれば、
ここではフォルダを想定する。
隣接リスト(Adjacency List)
Tree-Structure/adjacency_list at main · teitei-tk/Tree-Structure · GitHub
単純に考えると、各フォルダに親のフォルダを参照させるやり方が想定される。 しかし、このままだとフォルダ構成が深い場合、単一のSQLで取得することが難しい。実際に見てみる。
フォルダ構成は下記

table
CREATE TABLE IF NOT EXISTS `adjacency_list` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `parent_id` bigint(20), `name` varchar(255) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ノードデータ
INSERT INTO `adjacency_list` ( parent_id, name ) VALUES ( null, "Home" ), ( 1, "Downloads" ), ( 2, "20201126" ), ( 1, "Desktop" ), ( 1, "Documents" ), ( 5, "Adobe" ), ( 6, "PremierePro" ), ( 6, "PhotoShop" )
このデータを一括で取得する場合は下記のSQLになる。
SELECT * FROM adjacency_list as al LEFT OUTER JOIN adjacency_list as al2 ON al.parent_id = al2.id LEFT OUTER JOIN adjacency_list as al3 ON al2.parent_id = al3.id LEFT OUTER JOIN adjacency_list as al4 ON al3.parent_id = al4.id
結果は下記の通りになる。
| id | parent_id | name | id | parent_id | name | id | parent_id | name | id | parent_id | name |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | NULL | Home | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 2 | 1 | Downloads | 1 | NULL | Home | NULL | NULL | NULL | NULL | NULL | NULL |
| 3 | 2 | 20201126 | 2 | 1 | Downloads | 1 | NULL | Home | NULL | NULL | NULL |
| 4 | 1 | Desktop | 1 | NULL | Home | NULL | NULL | NULL | NULL | NULL | NULL |
| 5 | 1 | Documents | 1 | NULL | Home | NULL | NULL | NULL | NULL | NULL | NULL |
| 6 | 5 | Adobe | 5 | 1 | Documents | 1 | NULL | Home | NULL | NULL | NULL |
| 7 | 6 | PremierePro | 6 | 5 | Adobe | 5 | 1 | Documents | 1 | NULL | Home |
| 8 | 6 | PhotoShop | 6 | 5 | Adobe | 5 | 1 | Documents | 1 | NULL | Home |
クエリを見ての通り階層分 n回 LEFT OUTER JOINで直近の子と親を取得しているが、 このクエリのままではすべてのフォルダを一括で取得することが出来ない。やるとしても大量かつ複雑なSQLが必要になる。
この隣接リストモデルの代替となるものには、下記のような設計がある。
- 経路列挙モデル(Path Enumeration)
- 入れ子集合モデル(Nested Set)
- 閉包テーブルモデル(Closure Table)など
順に解説をする
経路列挙 (Path Enumeration)
Tree-Structure/path_enumeration at main · teitei-tk/Tree-Structure · GitHub
経路列挙モデル(Path Enumeration)は先祖の系譜を表す文字列をノードとして扱うことで解決している。
具体的にはUnixのディレクトリ構造。eg. /bin/sh
テーブル定義
CREATE TABLE IF NOT EXISTS `path_enumeration` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `path` varchar(1000), `name` varchar(255) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ノードデータ
INSERT INTO `path_enumeration` ( path, name ) VALUES ( "1/", "Home" ), ( "1/2/", "Downloads" ), ( "1/2/3/", "20201126" ), ( "1/4/", "Desktop" ), ( "1/5/", "Documents" ), ( "1/5/6/", "Adobe" ), ( "1/5/6/7/", "PremierePro" ), ( "1/5/6/8/", "PhotoShop" );
結果
| id | path | name |
|---|---|---|
| 1 | 1/ | Home |
| 2 | 1/2/ | Downloads |
| 3 | 1/2/3/ | 20201126 |
| 4 | 1/4/ | Desktop |
| 5 | 1/5/ | Documents |
| 6 | 1/5/6/ | Adobe |
| 7 | 1/5/6/7/ | PremierePro |
| 8 | 1/5/6/8/ | PhotoShop |
例として、PhotoShopディレクトリのすべての先祖を取得するクエリは下記のようになる。
SELECT pe.*, CONCAT(pe.path, "%") as LikeQuery FROM path_enumeration AS pe WHERE "1/5/6/8" LIKE CONCAT(pe.path, "%");
結果
| id | path | name | LikeQuery |
|---|---|---|---|
| 1 | 1/ | Home | 1/% |
| 5 | 1/5/ | Documents | 1/5/% |
| 6 | 1/5/6/ | Adobe | 1/5/6/% |
| 8 | 1/5/6/8/ | PhotoShop | 1/5/6/8% |
CONCAT(pe.path, "%")が味噌。クエリ結果にLikeQueryを表示しているのでわかると思うが先祖のパスがLIKEパターンマッチしている。具体的には下記のノードと一致する。
1/%1/5/%1/5/6/%
子孫を取得する場合にはLIKE句の引数を逆にする。
SELECT pe.*, CONCAT("1/5/", "%") AS LikeQuery FROM path_enumeration AS pe WHERE pe.path LIKE CONCAT("1/5/", "%");
結果
| id | path | name | LikeQuery |
|---|---|---|---|
| 5 | 1/5/ | Documents | 1/5/% |
| 6 | 1/5/6/ | Adobe | 1/5/% |
| 7 | 1/5/6/7/ | PremierePro | 1/5/% |
| 8 | 1/5/6/8/ | PhotoShop | 1/5/% |
1/5/%は下記のノードと一致する。
1/5/1/5/6/1/5/6/7/1/5/6/8/
ノードの挿入
Home以下にMusicというノードを挿入する。
Query
INSERT INTO `path_enumeration` ( name ) VALUES ( "Music" ); Update `path_enumeration` SET path = CONCAT(( SELECT x.path FROM ( SELECT path FROM path_enumeration WHERE id = 1 ) as x ), LAST_INSERT_ID()) WHERE id = LAST_INSERT_ID();
主キーがAutoIncremntの場合、挿入時点では自分のIDがわからないのでpathを構築出来ない。一旦pathを除いたノードを挿入し、Update文でpathを更新する。
デメリット
- pathの管理はアプリケーションのコードに依存することになる。validationが複雑になりメンテンス性の心配が残る。
- pathの型はvarchar型で、無限に保存出来るわけではない。
入れ子集合(Nested Set)
Tree-Structure/nested_set at main · teitei-tk/Tree-Structure · GitHub
入れ子集合(Nested Set)は、直近の親ではなく、子孫の集合に関する情報を各ノードに保存する。各ノードのnsleftおよびnsrightと呼ばれる数値で階層を表現する。
テーブル定義
CREATE TABLE IF NOT EXISTS `nested_set` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, `nsleft` integer NOT NULL, `nsright` integer NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ノードデータ
INSERT INTO `nested_set` ( name, nsleft, nsright ) VALUES ( "Home", 1, 15 ), ( "Downloads", 2, 5 ), ( "20201126", 3, 4 ), ( "Desktop", 6, 7 ), ( "Documents", 8, 14 ), ( "Adobe", 9, 12 ), ( "PremierePro", 10, 11 ), ( "PhotoShop", 12, 13 )
| id | name | nsleft | nsright |
|---|---|---|---|
| 1 | Home | 1 | 15 |
| 2 | Downloads | 2 | 5 |
| 3 | 20201126 | 3 | 4 |
| 4 | Desktop | 6 | 7 |
| 5 | Documents | 8 | 14 |
| 6 | Adobe | 9 | 12 |
| 7 | PremierePro | 10 | 11 |
| 8 | PhotoShop | 12 | 13 |
例として、Documents以下のノードを取得する場合は下記のクエリになる。
SELECT s2.* FROM nested_set as s1 INNER JOIN nested_set as s2 ON s2.nsleft BETWEEN s1.nsleft AND s1.nsright WHERE s1.id = 5
BEETWEENで範囲指定しているところが味噌。この例で言うと、id = 5であるDocumentsのnsleft.8とnsright.14の間にある、nsleftの値を持っているすべての子孫ノードを取得することが出来る。
| id | name | nsleft | nsright |
|---|---|---|---|
| 5 | Documents | 8 | 14 |
| 6 | Adobe | 9 | 12 |
| 7 | PremierePro | 10 | 11 |
| 8 | PhotoShop | 12 | 13 |
先祖を取得する場合は逆にする。
SELECT s1.*, s2.* FROM nested_set as s1 INNER JOIN nested_set as s2 ON s1.nsleft BETWEEN s2.nsleft AND s2.nsright WHERE s1.id = 5
id = 5であるDocumentsのnsleft.8の値が nsleftとnsrightの間にあるすべてのノードを取得出来る。この例でいうと、nsleftが1でnsrightが15であるHomeが該当する。
デメリット
- ノードの挿入や移動などの際にツリー構造の操作が他のモデルに比べて複雑になる。そのためノードの挿入が頻繁に求められる場合は最適解にはならない。
- ノードの挿入では新しいノードの左(nsleft)の値より大きいすべての左右のノードの値を計算し直す必要がある。
閉包テーブル(Closure Table)
Tree-Structure/closure_table at main · teitei-tk/Tree-Structure · GitHub
閉包テーブル(Closure Table)は今までもモデルとは違い直接の親子関係だけではなく、ツリー全体のパスをテーブルに格納する。
テーブル定義
今までのようなフォルダの定義に加えて、TreePathというテーブル定義する。
CREATE TABLE IF NOT EXISTS `closure_table` ( `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE IF NOT EXISTS `tree_paths` ( `ancestor` BIGINT(20) UNSIGNED NOT NULL, `descendant` BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (`ancestor`, `descendant`), FOREIGN KEY (`ancestor`) REFERENCES closure_table(`id`), FOREIGN KEY (`descendant`) REFERENCES closure_table(`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
閉包テーブルでは今までモデルとは違い、ツリー構造のデータをTreePathsテーブルに保存する。このテーブルの各行には先祖(ancestor)/子孫(descendant)を共有するノードの組み合わせを保存する。これはツリー状の離れた位置にあるノードも含めたすべてのノードが対象になる。また、各行のノードには自分自身を参照するレコードも追加する。
ノードデータ
INSERT INTO `closure_table` ( name ) VALUES ( "Home" ), ( "Downloads" ), ( "20201126" ), ( "Desktop" ), ( "Documents" ), ( "Adobe" ), ( "PremierePro" ), ( "PhotoShop" ); INSERT INTO `tree_paths` ( ancestor, descendant ) VALUES ( 1, 1 ), ( 1, 2 ), ( 1, 3 ), ( 1, 4 ), ( 1, 5 ), ( 1, 6 ), ( 1, 7 ), ( 1, 8 ), ( 2, 2 ), ( 2, 3 ), ( 3, 3 ), ( 4, 4 ), ( 5, 5 ), ( 5, 6 ), ( 5, 7 ), ( 5, 8 ), ( 6, 6 ), ( 6, 7 ), ( 6, 8 ), ( 7, 7 ), ( 8, 8 );
closure_table
| id | name |
|---|---|
| 1 | Home |
| 2 | Downloads |
| 3 | 20201126 |
| 4 | Desktop |
| 5 | Documents |
| 6 | Adobe |
| 7 | PremierePro |
| 8 | PhotoShop |
tree_paths
| ancestor | descendant |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 1 | 3 |
| 2 | 3 |
| 3 | 3 |
| 1 | 4 |
| 4 | 4 |
| 1 | 5 |
| 5 | 5 |
| 1 | 6 |
| 5 | 6 |
| 6 | 6 |
| 1 | 7 |
| 5 | 7 |
| 6 | 7 |
| 7 | 7 |
| 1 | 8 |
| 5 | 8 |
| 6 | 8 |
| 8 | 8 |
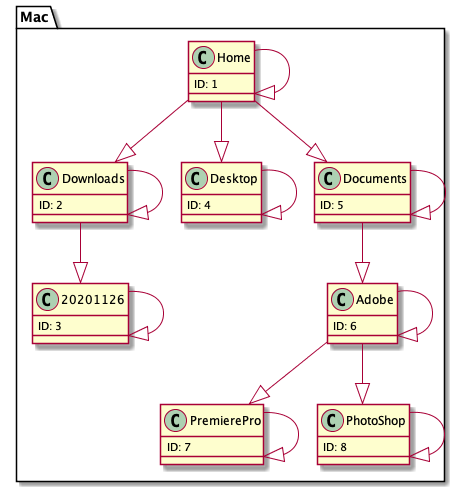
ノードを取得するクエリは入れ子集合よりも更に簡単になる。ID=2のDownloads以下を取得するにはtree_pathsをJoinして、anestor(先祖)が2の行を探すだけ。
SELECT c.* FROM closure_table as c INNER JOIN tree_paths as t ON c.id = t.descendant WHERE t.ancestor = 2
result
| id | name |
|---|---|
| 2 | Downloads |
| 3 | 20201126 |
先祖の取得も簡単で、先程のクエリのancestorとdescendantを逆に書くだけ。ID=8の先祖を取得する。
SELECT c.* FROM closure_table as c INNER JOIN tree_paths as t ON c.id = t.ancestor WHERE t.descendant = 8
result
| id | name |
|---|---|
| 1 | Home |
| 5 | Documents |
| 6 | Adobe |
| 8 | PhotoShop |
新たにノードを挿入する場合、例えばID=4のDesktop以下にノードを挿入するには、まずclosure_tableにフォルダのデータを挿入する。
INSERT INTO `closure_table` ( name ) VALUES ( "Macintosh HD" )
次にID=4を子孫として参照する行の集合を取得し、子孫をLAST_INSERT_ID()で置き換えて新たに挿入する。
INSERT INTO `tree_paths` ( ancestor, descendant ) SELECT t.ancestor, LAST_INSERT_ID() as descendant FROM tree_paths as t WHERE t.descendant = 4 UNION ALL SELECT LAST_INSERT_ID(), LAST_INSERT_ID()
INSERT句で利用しているSELECT句の結果は下記になる。
| ancestor | descendant |
|---|---|
| 1 | 9 |
| 4 | 9 |
| 9 | 9 |
- 先祖が1(Home)で、子孫が9(Macintosh HD)
- 先祖が4(Desktop)で、子孫が9(Macintosh HD)
- 先祖が9(Macintosh HD)で、子孫が9(Macintosh HD)
となっていることがわかる。
ノードを削除する場合、例えば先程挿入した`ID=9'を削除する場合には、子孫として9を参照するすべての行を削除する。具体的に削除するレコードは上記の結果である。
DELETE FROM `tree_paths` WHERE descendant = LAST_INSERT_ID();
サブツリー全体、例えばID=6とその子孫をすべて削除するには、子孫としてID=6を参照する全ての行と、ID=6の子孫を子孫として参照するすべての行を削除する。
具体的には下記のSQLになる
DELETE FROM `tree_paths` WHERE descendant IN ( SELECT x.id FROM ( SELECT descendant as id FROM `tree_paths` WHERE ancestor = 6 ) as x )
DELETE文の条件に利用しているSELECT文の結果は下記
SELECT x.id FROM ( SELECT descendant as id FROM `tree_paths` WHERE ancestor = 6 )
結果
| id |
|---|
| 6 |
| 7 |
| 8 |
IDが6, 7, 8と、ID=6以下のツリーが削除されることがわかる。
結局どの設計を使うべきなのか
| 設計 | 子へのクエリ実行 | ツリーへのクエリ実行 | 挿入 | 削除 | 参照整合性維持 |
|---|---|---|---|---|---|
| 隣接リスト | 簡単 | 難しい | 難しい | 簡単 | 可能 |
| 経路列挙モデル | 簡単 | 簡単 | 簡単 | 簡単 | 不可 |
| 入れ子集合モデル | 難しい | 難しい | 難しい | 難しい | 不可 |
| 閉包テーブルモデル | 簡単 | 簡単 | 簡単 | 簡単 | 可能 |
個人的な意見
仕様にもよりますが、消去法で閉包テーブル設計かなとなります。
隣接リスト
単純に筋が悪い設計だと考えている。要件がかなり簡易な場合(一つの親しか持たない)にはありかもしれないが、そのような仕様は時間が経つに連れて変わっていくし、すぐに新しく親を設計したいと出てくる。それを考えると別の手法を設計すべきと考える。
経路列挙
筋は良いが、経路列挙のpathの管理が辛そうと考えている。アプリケーション側でpathのValidationなどが長大になりそうなのを考えるとメンテンス性に欠ける。メンテンス性に欠けるということはバグの温床になりやすい。そう考えると閉包テーブルモデルの方が良いと考える。
また、pathに複数の値(フォルダの経路)を格納する事はSQLアンチパターンのジェイウォークに当てはまる。
www.slideshare.net
入れ子集合モデル
ノードの挿入や移動などの際にツリー構造の操作が他のモデルに比べて複雑になるのが欠点。挿入や更新が多い要件には向いていない。レコード数が大量にあると更新に時間がかかる。個人的にはクエリが複雑になる事が一番の欠点。コードもクエリも設計もシンプルに収めたほうが良いと考える人間なので、筋は良いが、それなら閉包テーブルモデルを採用したほうが良いと判断。
閉包テーブル
ツリー構造を格納するテーブルのレコードが爆発的に増えるが、その分取得、挿入、更新、削除もシンプルに出来る。トレードオフだが、複雑性が増して不具合の温床になるよりはレコード数が増えるデメリットを受け入れたほうが長期的に見て良いと思っている。